Venue
Parking Information
For attendees who plan on driving, the Student Center can provide on-site parking lots. Attendees can stop at the Student Center Parking Structure Parking Kiosk, which is located on the corner of West Peltason Drive and Pereira Drive. Please [click here] to see the detailed directions. Attendees are to pay the attendant $10 for a general UCI parking permit.
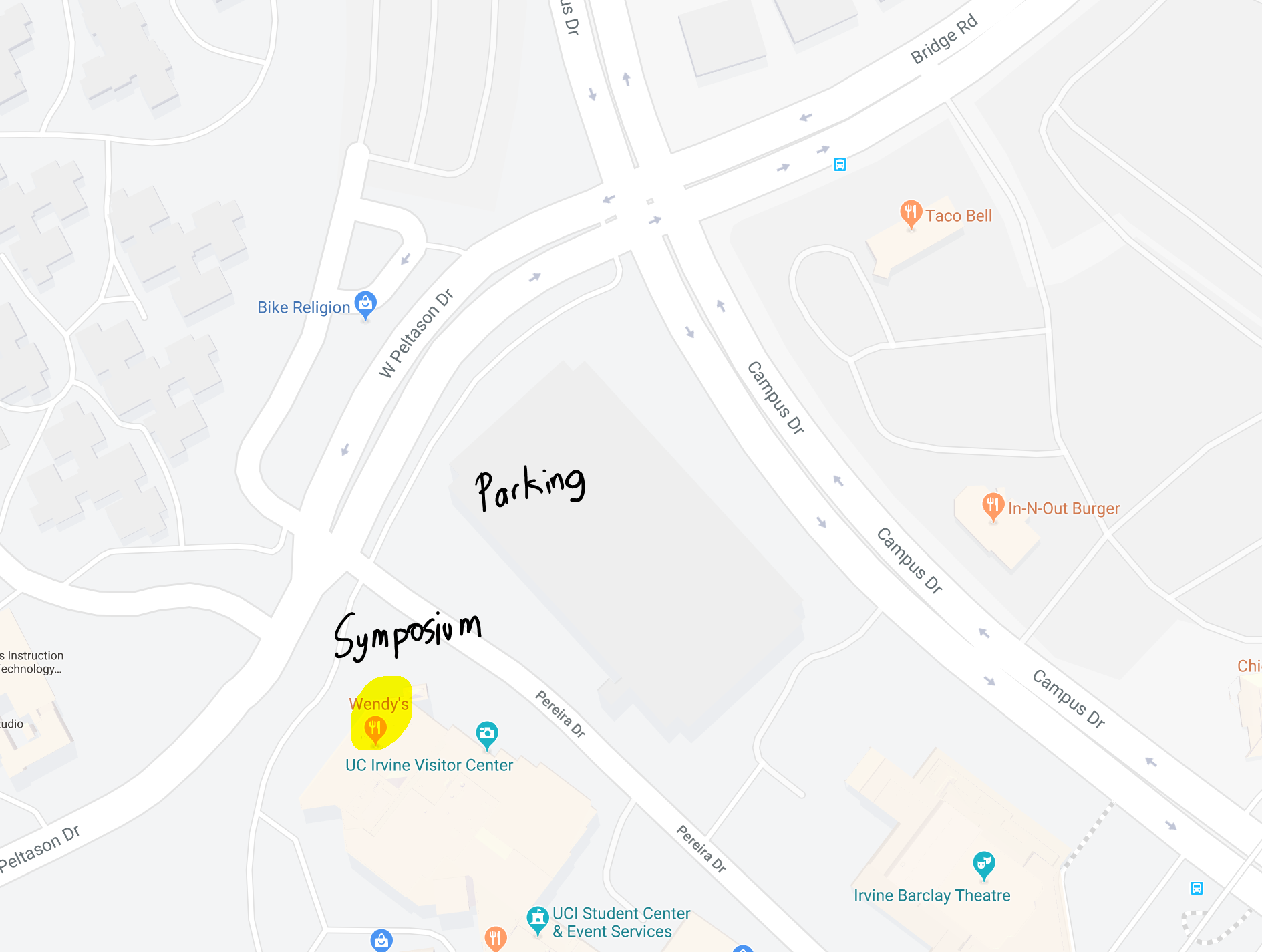
After exiting the Student Center Parking Structure, attendees can walk across the street to the Student Center and enter through the Conference Center doors. The right sides are the Doheny Beach meeting rooms. Please check in at the registration desk to receive the name badge and packet folder.














